本文推荐了一篇关于上下文工程的综述文章,指出上下文工程对于深度使用AI工具的重要性,并总结了文章的核心内容:提供了上下文工程的清晰框架,包括定义、基础组件、系统实现、评估方法及未来研究方向;阐述了上下文工程的必要性,即通过优化上下文信息来提升AI表现,解决AI固有缺陷,提高资料利用率;并介绍了上下文工程面临的挑战,包括长度缩放和多模态与结构化缩放。文章强调阅读原文的重要性,并建议将AI作为辅助工具,享受学习和思考的过程。
01. 为什么推荐读这篇上下文工程的综述?
为什么我会想要去看上下文工程呢?因为每一个尝试着深度使用AI工具的人,都免不了要一遍一遍调试提示词——你很少能够一次性拿到理想的结果,哪怕你已经在和这个世界上号称最顶级的AI合作。
这大概率不是因为你的要求超过了AI的能力边界,而是因为AI没有拿到足够的信息。
我最初只是想要把提示词写得更好一点,就去扒了一下提示词工程。然后发现网上都在说提示词工程被上下文工程给取代了,于是也去看了一眼这篇关于“上下文工程”的综述——A Survey of Context Engineering for Large Language Models。
推荐想要了解AI的人都不要错过:https://arxiv.org/html/2507.13334v1
我非常的惊喜,因为它提供了一个特别清晰的框架来回答了“上下文工程是什么、为什么、怎么做”的问题。它描绘了一个“全景地图”来让读者理解现在最火的AI系统“面临什么样的限制”,“已经实施了什么样的解决方案”,“还有什么待解决的问题”。
更重要的是,我觉得它是一个“由浅入深”的研究指南——这篇综述总共引用了1401篇文献,但是结构非常清晰,表达非常简洁。
框架的魅力就是把以前你找到的各种乱七八糟的碎片,都有条理地排列整齐,让你不再到处抓瞎,知道大概有几条路,从而分析你想要去哪一条路。
对于小白来说,就算这篇文章读起来一知半解,也可以通过文章对于各种AI系统的概述来迅速理解AI世界的轮廓和脉络;对于想要深入研究的人来说,可以顺着文章的引用文献继续去挖掘,了解具体算法和系统的设计细节。
(看看下面这张信息高度浓缩的“上下文工程”框架图,是不是非常清晰?)
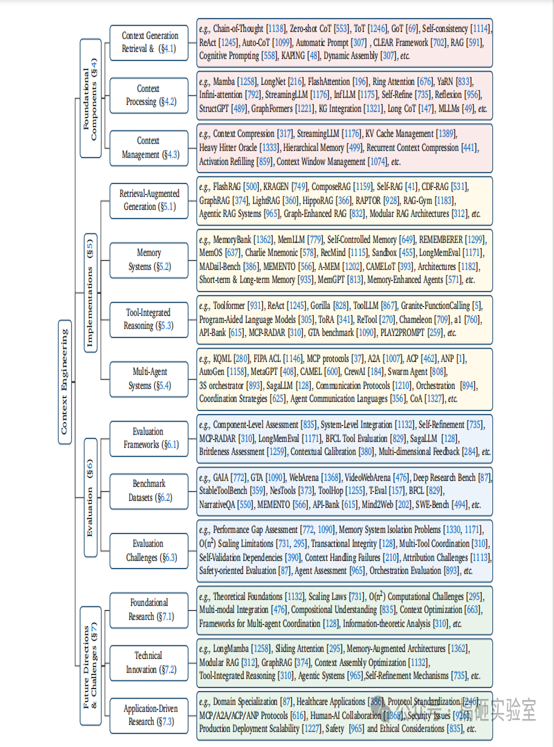 02. 综述文章的结构
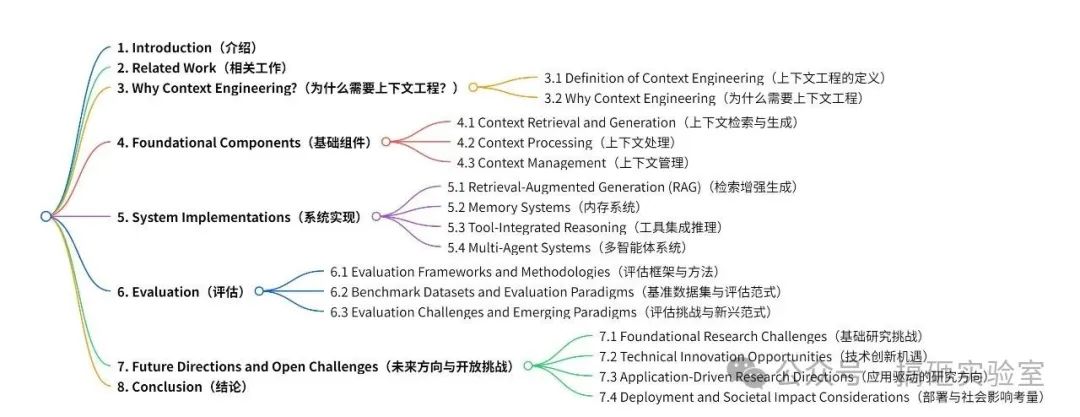
02. 综述文章的结构
这篇综述文章的结构可见下面的思维导图,核心是以下四个部分:
·
定义+介绍上下文工程的“基础组件”;
·
介绍在“基础组件”上形成的几个重要的“系统实现”;
·
介绍评估上下文工程表现的系统性方法以及评估后的核心发现;
·
指出未来的研究方向;
 03. “上下文工程”是什么以及为什么需要它?
03. “上下文工程”是什么以及为什么需要它?
我在这里先说一下我的理解+提出部分我觉得很给我启发的原文。
同一个大语言模型,在不同的人手里使用效果是不一样的。大语言模型就像是一个对“你本人”和“你的任务”一无所知,但是干活能力特别强的高级实习生。
在这个高级实习生能力不变的条件下,TA能不能交付出你满意的结果,取决于你这个领导能不能让TA融入你的系统,了解整个事情的前因后果。
这跟工作中干活是一样的道理——如果只听到领导说“调研一下XX竞品”就开始干活,容易跑偏十里地不自知。最好先跟领导确认“这次调研的汇报对象是谁,调研任务产生的背景是什么,有没有什么重点关注的方向”。然后还要结合你长期积累的业务认知,才能够交付出正中红心的答案。
大模型的表现也取决于TA获取到的“上下文”,没有这些信息,这个AI有千亿参数也不会表现得让你满意。更可况我们对于LLM的要求已经越来越高,从期待LLM完成简单的指令服从,到期待TA们成为复杂多面的核心推理引擎。
这意味着我们和LLM交互的方式不能够仅仅是静态的、单一的、碎片化的“prompt”,而是更加高级和复杂的工程系统。
上下文工程会在以下3个方面带来好处。
第一个是解决AI的固有缺陷。
最明显的就是,AI能够获取的上下文是有限的——AI有一个“上下文窗口”,一旦我们输入的信息超过了这个限度,AI就无法一次性处理了。
同时AI处理信息消耗的资源量级很大,要远超我们人类处理信息消耗的资源。资源分为“时间”和“空间”两个维度,分别对应了AI处理信息时面临的“性能”和“内存”瓶颈。例如Transformer架构的模型,要储存输入序列每一个对象的K、V、Q值,这意味着当序列长度非常大时,注意力矩阵的计算和储存会消耗大量的计算资源;但是如果用LSTM,则并行计算的程度很低,处理超长序列的时间会被狠狠拉长,变得不可承受。
还有AI生成的内容可靠性是不足的。按照论文的总结,不可靠表现在:LLMs频繁出现幻觉胡言乱语、不遵循输入上下文、对输入变化的不当敏感,以及会生产语法看似正确但缺乏语义深度或连贯性的内容。
如何避免这些AI固有缺陷,让模型完成复杂任务,要求极其精巧的、系统的架构设计,这是上下文工程的领域。
第二个好处是提升AI的表现。这个提升不是通过重新设计大模型架构,或者重新训练大模型得来的,就是通过良好组织的上下文来实现的。相当于在基座模型能力不变的前提下,找到极致发挥TA能力的方案。比如思维链方法,能够通过中间步骤实现复杂推理,显著提升模型推理的正确性。
第三个好处是提升资料的利用率。我们都知道在训练大模型的时候需要海量的数据,上下文工程在“把资料物尽其用”方面发力。它们会利用上下文线索和先验知识来优化上下文长度,同时保持回答的质量,这对于那些资料匮乏的领域特别有价值。
总结来说,如何充分利用已有的上下文窗口,极致压榨已经获得的资源,得到质量超高的模型输出,是“上下文工程”研究的核心。
用论文官方的话来表达:
“上下文C是一个动态结构化的信息组件集合c1、c2,...,cn。这些组件通过一系列函数进行获取、过滤和格式化处理,最终由高级函数A进行协调和组装。
上下文工程要解决的是这样一个问题:在(算力和上下文窗口等)约束下,寻找一组理想的上下文生成函数集,以最大化LLM输出的预期质量。”
你仔细思考一下跟人类是一样的——你自己也只是能够拥有有限记忆的生物,你自己也要消耗精力和时间去实施动作、完成任务。
“上下文工程”跟你在搭建属于自己的“决策机制”、“标准化流程”和“知识管理系统”没有什么不同,是不是有些细思极恐?
上下文工程是找到一系列基础信息组件,并且用一个总协调函数把他们组织起来,这些信息可以大概分为以下几个类别,我觉得这个分类框架也可以给我们使用AI的人一些启示:
·
C_instr :系统指令和规则(上下文检索与生成)。
·
C_Know:外部知识,通过如检索增强生成(RAG)等函数或从集成知识图谱中获取。
·
C_tools:可用的外部工具的定义和签名(涉及能力是函数调用与工具集成推理)。
·
C_mem:先前交互中的持久信息(内存系统;上下文管理系统)。
·
C_state:用户、环境或多智能体系统的动态状态(多智能体系统与编排)。
·
C_query:用户的即时请求。
04. Context Scaling面临的挑战:
论文特别指出了Context Scaling的两个维度上的挑战。用我自己的话来理解就是,如果想要把上下文处理好,有两个维度的困难需要攻克,这两个维度共同定义了上下文信息处理的范围和复杂程度。
第一个维度是长度缩放(Length Scaling),也就是单次处理超长上下文时面临的挑战。首先要研究怎么把上下文窗口搞得长一点,其次还要弄清楚上下文很长之后,大模型要怎么对这么一大段信息保持连贯性的理解,不要遗忘、瞎编,还能在各种任务中灵活使用(像是人类一样)。
这里涉及了复杂的注意力机制(attention
mechanisms)和内存管理技术(memory management techniques)的研究。

第二个维度是多模态与结构化缩放(Multi-modal
and Structural Scaling)。我们现在要求大模型处理的不是只有文本信息了,而是图片、音频、视频、大型数据库等各种模态合并在一起的综合信息。同时,我们也不满足于只拥有静态知识的大模型,我们需要模型理解和处理动态变更的信息。
因此上下文工程要有动态编排和自适应的能力,并且把多模态的信息组织起来给到大模型。这涉及了更系统化的信息管理,包括时间、空间、参与者状态、意图理解、文化相关的上下文管理。

现代上下文工程需要应对上述两个维度的挑战。处理的数据类型包含:冗长文本信息、结构化知识图谱(knowledge graphs)、多模态输入(text, images, audio,
video)、时间序列、人类自然理解的隐含上下文线索。
研究内容从参数缩放(parameter scaling)转向开发能够理解复杂、模糊上下文的系统,目的是让AI能够面对复杂世界完成复杂任务。
05. 小结:
这篇先介绍了一下综述论文里面提出的“上下文工程的定义”和“为什么需要上下文工程”的部分,下篇文章继续介绍论文里面提出的“上下文工程的基础组件”和“系统实现”框架。
这里我还是要再次强调我的观点:建议感兴趣的朋友都去阅读原文,别人或者AI的总结其实都是不够的,信息漏损太大了。
没有任何人或者AI能够代替你去进行核心体验,核心体验包括学习、生活、输出、创造等等等。
截至25年7月,拥有最长上下文窗口的模型为Magic.dev 的 LTM-2-Mini,据说一次性可以处理1个亿token,相当于一次性记住
750 部10万字小说的细节。
但是就算AI能够一次性读1个亿的token,你的人生核心主角仍然是你自己,你仍然需要自己去吸收、理解、组织,让知识改你脑子里的神经回路,而不是AI的。
AI的能力要为你服务而不是替代你去体验生活,我最近很喜欢的合作方式是让AI作为“粗处理”的助理,TA需要帮我解释我不熟悉的专业术语,需要帮我提炼出文章的结构,需要帮我调查一些示例,这些都是为了我更好的消化原文做准备。
最终我还是需要去阅读原文,在上面写写画画,做我自己的备注,就算这会花上一周的时间。
祝愿我们都享受learning的过程~
原文出自:https://mp.weixin.qq.com/s/USpZcks296XUUe4ev41wCg
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip