本文将讲述从PDF中将表格、图像和纯文本提取出文本信息的完整过程,主要内容:
• PDF的分类:文本型、OCR和扫描型
• 针对不同类型的PDF,我们提取的理论依据
• 环境安装
• 编写提取纯文本的函数
• 编写提取图像中文本的函数
• 编写提取表格的文本内容的函数
• 最后的整合处理
本文将讲述从PDF中将表格、图像和纯文本提取出文本信息的完整过程,主要内容:
- PDF的分类:文本型、OCR和扫描型
- 针对不同类型的PDF,我们提取的理论依据
- 环境安装
- 编写提取纯文本的函数
- 编写提取图像中文本的函数
- 编写提取表格的文本内容的函数
- 最后的整合处理
写在前面
随着大型语言模型(LLM)的应用不断发展,从简单的文本摘要和翻译,到基于情绪和财务报告主题预测股票表现,再到复杂的检索(如RAG),都需要我们首先从真实世界提取文本数据。
有许多类型的文档共享这种非结构化信息,从网络文章、博客文章到手写信件和图表。然而,这些文本数据的很大一部分是以PDF格式存储和传输的(我们做的更极端,即使原先不是PDF,一般也会先把文字进行处理好,转换为PDF)。
因此,从PDF文档中提取信息,是很多类似RAG这样的应用第一步要处理的事情,在这个环节,我们需要做好三件事:
·
提取出来的文本要保持信息完整性,也就是准确性;
·
提出的结果需要有附加信息,也就是要保存元数据;
·
提取过程要完成自动化,也就是流程化。
然而,在我们开始之前,我们需要指定目前不同类型的pdf,更具体地说,是出现最频繁的三种:
1.
机器生成的pdf文件:这些pdf文件是在计算机上使用W3C技术(如HTML、CSS和Javascript)或其他软件(如Adobe Acrobat、Word或Typora等MarkDown工具)创建的。这种类型的文件可以包含各种组件,例如图像、文本和链接,这些组件都是可以被选中、搜索和易于编辑的。
2.
传统扫描文档:这些PDF文件是通过扫描仪、手机是的扫描王这样的APP从实物上扫描创建的。这些文件只不过是存储在PDF文件中的图像集合。也就是说,出现在这些图像中的元素,如文本或链接是不能被选择或搜索的。本质上,PDF只是这些图像的容器而已。
3.
带OCR的扫描文档:这种类似有点特殊,在扫描文档后,使用光学字符识别(OCR)软件识别文件中每个图像中的文本,将其转换为可搜索和可编辑的文本。然后软件会在图像上添加一个带有实际文本的图层,这样你就可以在浏览文件时选择它作为一个单独的组件。但是有时候我们不能完全信任OCR,因为它还是存在一定几率的识别错误的。
另外还有一种情况是,尽管现在越来越多的机器安装了OCR系统,可以识别扫描文档中的文本,但仍然有一些文档以图像格式包含整页。当你读到一篇很棒的文章时,你想选中一个句子,但却选择了整个页面。这可能是由于特定OCR程序的限制或OCR根本就可有介入。为了避免在最终本文提取的时候遗漏这些“看上去像文本的图片”,我在创建过程中需要考虑做一些处理。
理论方法
考虑到所有上面说的几种不同类型的PDF文件格式,对PDF的布局进行初步分析以确定每个组件所需的适当工具就很重要了。
更具体地说,根据此分析的结果,我们将应用适当的方法从PDF中提取文本,无论是在具有元数据的语料库块中呈现的文本、图像中的文本还是表格中的结构化文本。在没有OCR的扫描文档中,从图像中识别和提取文本将非常繁重。此过程的输出将是一个Python字典(dictionary),其中包含为PDF文件的每个页面提取的信息。该字典(dictionary)中的每个键将表示文档的页码,其对应的值将是一个列表,其中包含以下5个嵌套列表:
1.
从语料库中每个文本块提取的文本
2.
每个文本块中文本的格式,包括font-family和font-size
3.
从页面中的图像上提取的文本
4.
以结构化格式从表格中提取的文本
5.
页面的完整文本内容

图1:文本提取示意
这样,我们可以实现对每个PDF组件提取的文本的更合乎逻辑的分离,并且有时可以帮助我们更容易地检索通常出现在特定组件中的信息(例如,LOGO中的公司名称、表格中各数据的对应关系)。此外,从文本中提取的元数据,如font-family和font-size,可以用来轻松地识别文本标题或高亮的重要文本,这将帮助我们进一步分离,或者在多个不同的块中对文本进行合并、排序等后续处理。最后,以LLM能够理解的方式保留结构化表信息将显著提高对提取数据中关系的推理质量。然后,这些信息可以在最终输出的时候保留它原本的格式。
您可以在下面的图片中看到这种方法的流程图。
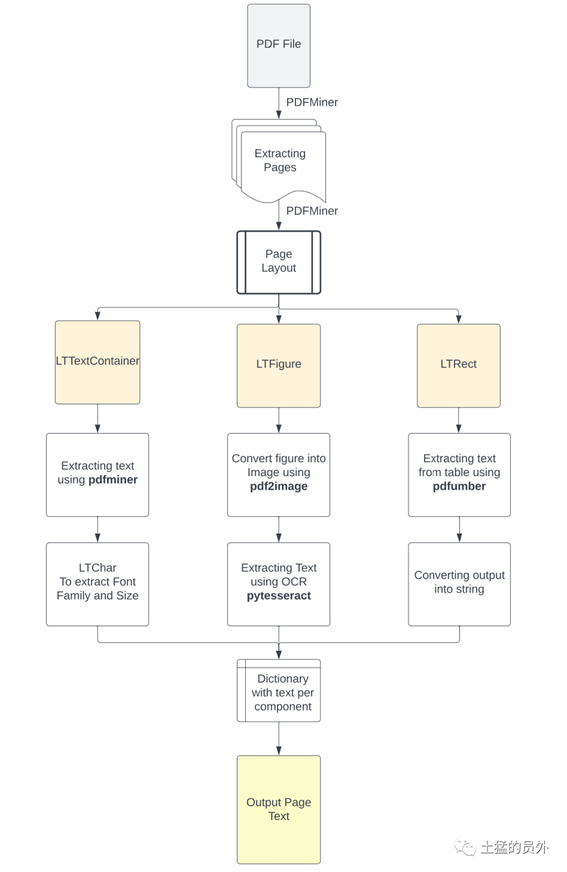
图2:PDF提取方法的具体流程,中间会有各种适配选择
安装所需的库
在我们开始使用PDF文本提取之前,应该安装必要的库。机器上首先需要安装Python 3.10或更高版本。你也可以安装最新的Anaconda,我装的就是它。
PyPDF2:从存储路径读取PDF文件。
pip install PyPDF2
Pdfminer :执行布局分析并从PDF中提取文本和格式。(.six版本的库是支持Python 3的版本)
pip install pdfminer.six
Pdfplumber:识别PDF页面中的table并从中提取信息。
pip install pdfplumber
Pdf2image:将裁剪后的PDF图像转换为PNG图像。
pip install pdf2image
PIL:读取PNG图像。
pip install Pillow
Pytesseract:从图像中提取文本使用OCR技术
这个安装起来有点棘手,因为首先,您需要安装Google
Tesseract OCR(链接在文章底部引用区),这是一个基于LSTM模型的OCR机器,用于识别行识别和字符模式。
如果你是Mac用户,你可以在你的终端上通过Brew安装它,这样就可以了。
brew install tesseract
对于Windows用户,可以参照以下步骤进行安装(https://linuxhint.com/install-tesseract-windows/)。安装软件后,需要将它们的可执行文件路径添加到计算机上的环境变量中。或者,也可以运行以下命令,使用以下代码直接将其路径包含在Python脚本中:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
然后就可以安装Python库了
pip install pytesseract
最后,我们将在程序中导入所有库:
# 读取PDF
import PyPDF2
# 分析PDF的layout,提取文本
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
# 从PDF的表格中提取文本
import pdfplumber
# 从PDF中提取图片
from PIL import Image
from pdf2image import convert_from_path
# 运行OCR从图片中提取文本
import pytesseract
# 清除过程中的各种过程文件
import os
现在我们都准备好了,让我们来试一下这些库怎么样。
文档的布局(Layout)分析

图3:布局分析,理解什么是LOGO,什么是标题,什么是表格等
对于初步分析,我们使用PDFMiner的Python库将文档对象中的文本分离为多个页面对象,然后分解并检查每个页面的布局。PDF文件本身缺乏结构化信息,如我们可以一眼识别的段落、句子或单词等。相反,它们只理解文本中的单个字符及其在页面上的位置。通过这种方式,PDFMiner尝试将页面的内容重构为单个字符及其在文件中的位置。然后,通过比较这些字符与其他字符的距离,它组成适当的单词、句子、行和文本段落。为了实现这一点,PDFMiner使用高级函数extract_pages()从PDF文件中分离各个页面,并将它们转换为LTPage对象。
然后,对于每个LTPage对象,它从上到下遍历每个元素,并尝试将适当的组件识别为:
·
LTFigure:表示PDF中页面上的图形或图像的区域。
·
LTTextContainer:代表一个矩形区域(段落)中的一组文本行(line),然后进一步分析成LTTextLine对象的列表。它们中的每一个都表示一个LTChar对象列表,这些对象存储文本的单个字符及其元数据。
·
LTRect表示一个二维矩形,可用于在LTPage对象中占位区或者Panel,图形或创建表。
因此,使用Python对页面进行重构之后,将页面元素分类为LTFigure(图像或图形)、LTTextContainer(文本信息)或LTRect(表格),我们就可以选择适当的函数来更好地提取内容信息了。
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Iterate the elements that composed a page
for element in page:
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Function to extract text from the text block
pass
# Function to extract text format
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Function to convert PDF to Image
pass
# Function to extract text with OCR
pass
# Check the elements for tables
if isinstance(element, LTRect):
# Function to extract table
pass
# Function to convert table content into a string
pass
现在我们了解了流程的结构原理,接下来我们来创建从不同组件种提取文本所需的函数。
定义从PDF中提取文本的函数
从这里开始,从PDF中提取文本就非常简单了。
# 创建一个文本提取函数
def text_extraction(element):
# 从行元素中提取文本
line_text = element.get_text()
# 探析文本的格式
# 用文本行中出现的所有格式初始化列表
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# 遍历文本行中的每个字符
for character in text_line:
if isinstance(character, LTChar):
# 追加字符的font-family
line_formats.append(character.fontname)
# 追加字符的font-size
line_formats.append(character.size)
# 找到行中唯一的字体大小和名称
format_per_line = list(set(line_formats))
# 返回包含每行文本及其格式的元组
return (line_text, format_per_line)
因此,要从文本容器中提取文本,我们只需使用LTTextContainer元素的get_text()方法。此方法检索构成特定语料库框中单词的所有字符,并将输出存储在文本数据列表中。此列表中的每个元素表示容器中包含的原始文本信息。
现在,为了识别该文本的格式,我们遍历LTTextContainer对象,以单独访问该语料库的每个文本行。在每次迭代中,都会创建一个新的LTTextLine对象,表示该语料库块中的一行文本。然后检查嵌套的line元素是否包含文本。如果是,我们将每个单独的字符元素作为LTChar访问,其中包含该字符的所有元数据。从这个元数据中,我们提取两种类型的格式,并将它们存储在一个单独的列表中,对应于检查的文本:
·
字符的font-family,包括字符是粗体还是斜体
·
字符的font-size
通常,特定文本块中的字符往往具有一致的格式,除非某些字符以粗体突出显示。为了便于进一步分析,我们捕获文本中所有字符的文本格式的唯一值,并将它们存储在适当的列表中。
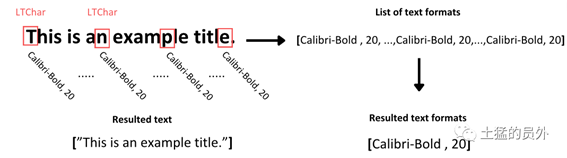
图4:获取字体、尺寸等元数据的过程
定义从图像中提取文本的函数
在这里,我认为这是一个更棘手的部分。如何处理在PDF中找到的图像中的文本?
首先,我们需要在这里确定存储在pdf中的图像元素与文件的格式不同,例如JPEG或PNG。这样,为了对它们应用OCR软件,我们需要首先将它们从文件中分离出来,然后将它们转换为图像格式。
# 创建一个从pdf中裁剪图像元素的函数
def crop_image(element, pageObj):
# 获取从PDF中裁剪图像的坐标
[image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1]
# 使用坐标(left, bottom, right, top)裁剪页面
pageObj.mediabox.lower_left = (image_left, image_bottom)
pageObj.mediabox.upper_right = (image_right, image_top)
# 将裁剪后的页面保存为新的PDF
cropped_pdf_writer = PyPDF2.PdfWriter()
cropped_pdf_writer.add_page(pageObj)
# 将裁剪好的PDF保存到一个新文件
with open('cropped_image.pdf', 'wb') as cropped_pdf_file:
cropped_pdf_writer.write(cropped_pdf_file)
# 创建一个将PDF内容转换为image的函数
def convert_to_images(input_file,):
images = convert_from_path(input_file)
image = images[0]
output_file = "PDF_image.png"
image.save(output_file, "PNG")
# 创建从图片中提取文本的函数
def image_to_text(image_path):
# 读取图片
img = Image.open(image_path)
# 从图片中抽取文本
text = pytesseract.image_to_string(img)
return text
为此,我们遵循以下流程:
1.
我们使用从PDFMiner检测到的LTFigure对象的元数据来裁剪图像框,利用其在页面布局中的坐标。然后使用PyPDF2库将其保存为新的PDF文件。
2.
然后,我们使用pdf2image库中的convert_from_file()函数将目录中的所有PDF文件转换为图像列表,并以PNG格式保存它们。
3.
最后,现在我们有了图像文件,我们使用PIL模块的image 包在脚本中读取它们,并实现pytesseract的image_to_string()函数,使用tesseract OCR引擎从图像中提取文本。
结果,这个过程返回图像中的文本,然后我们将其保存在输出字典中的第三个列表中。此列表包含从检查页面上的图像中提取的文本信息。
定义从表格中提取文本的函数
在本节中,我们将从PDF页面上的表格中提取更具逻辑结构的文本。这是一个比从语料库中提取文本稍微复杂的任务,因为我们需要考虑信息的粒度和表中呈现的数据点之间形成的关系。
虽然有几个库用于从pdf中提取表数据,其中Tabula-py是最著名的库之一,但我们已经确定了它们在功能上的某些限制。
在我们看来,最明显的问题来自于库在表的文本中使用换行特殊字符\n来标识表的不同行。这在大多数情况下工作得很好,但是当单元格中的文本被包装成2行或更多行时,它无法正确捕获,从而导致添加不必要的空行并丢失提取的单元格的上下文。
当我们尝试使用tabula-py从一个表中提取数据时,你可以看到下面的例子:
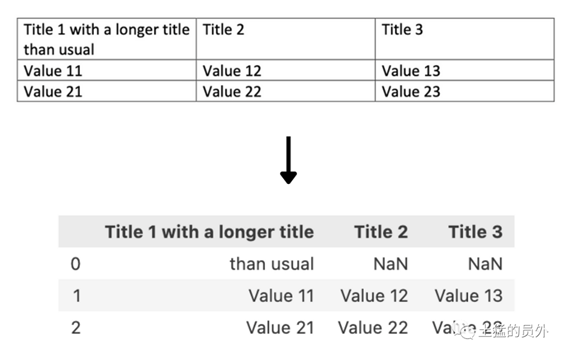
图5:提取表格信息,虽然转化为文本了,但是我们依然可以保留表格的信息
然后,提取的信息以Pandas DataFrame而不是字符串的形式输出。在大多数情况下,这可能是一种理想的格式,但是在考虑文本的Transformers的情况下,这些结果需要在输入到模型之前进行转换。
出于这个原因,出于各种原因,我们使用了pdfplumber库来处理这个任务。首先,它是基于pdfminer构建的。我们初步分析时用了六个,也就是说里面有类似的物品。此外,它的表检测方法基于行元素及其交点,这些交点构建包含文本的单元格,然后是表本身。这样,在确定表的单元格之后,我们就可以提取单元格中的内容,而不必携带需要呈现的行数。然后,当我们拥有表的内容时,将其格式化为类似表的字符串,并将其存储在适当的列表中。
# 从页面中提取表格内容
def extract_table(pdf_path, page_num, table_num):
# 打开PDF文件
pdf = pdfplumber.open(pdf_path)
# 查找已检查的页面
table_page = pdf.pages[page_num]
# 提取适当的表格
table = table_page.extract_tables()[table_num]
return table
# 将表格转换为适当的格式
def table_converter(table):
table_string = ''
# 遍历表格的每一行
for row_num in range(len(table)):
row = table[row_num]
# 从warp的文字删除线路断路器
cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row]
# 将表格转换为字符串,注意'|'、'\n'
table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n')
# 删除最后一个换行符
table_string = table_string[:-1]
return table_string
为了实现这一点,我们创建了两个函数,extract_table()用于将表的内容提取到一个列表的列表中,table_converter()用于将这些列表的内容连接到一个类似表的字符串中。
extract_table()函数中:
1.
我们打开PDF文件。
2.
我们导航到PDF文件的检查页面。
3.
从pdfplumber在页面上找到的表列表中,我们选择所需的表。
4.
我们提取表的内容,并将其输出到一个嵌套列表的列表中,该列表表示表的每一行。
在table_converter()函数:
1.
我们在每个嵌套列表中迭代,并清除其上下文中来自任何换行文本的任何不需要的换行符。
2.
我们通过使用|符号将行中的每个元素分开来连接它们,从而创建表单元格的结构。
3.
最后,我们在末尾添加一个换行符以移动到下一行。
这将产生一个文本字符串,该字符串将显示表的内容,而不会丢失其中显示的数据的粒度。
整合所有文本
现在我们已经准备好了代码的所有组件,让我们将它们全部添加到一个功能齐全的代码中。
# 查找PDF路径
pdf_path = 'OFFER 3.pdf'
# 创建一个PDF文件对象
pdfFileObj = open(pdf_path, 'rb')
# 创建一个PDF阅读器对象
pdfReaded = PyPDF2.PdfReader(pdfFileObj)
# 创建字典以从每个图像中提取文本
text_per_page = {}
# 我们从PDF中提取页面
for pagenum, page in enumerate(extract_pages(pdf_path)):
# 初始化从页面中提取文本所需的变量
pageObj = pdfReaded.pages[pagenum]
page_text = []
line_format = []
text_from_images = []
text_from_tables = []
page_content = []
# 初始化检查表的数量
table_num = 0
first_element= True
table_extraction_flag= False
# 打开pdf文件
pdf = pdfplumber.open(pdf_path)
# 查找已检查的页面
page_tables = pdf.pages[pagenum]
# 找出本页上的表格数目
tables = page_tables.find_tables()
# 找到所有的元素
page_elements = [(element.y1, element) for element in page._objs]
# 对页面中出现的所有元素进行排序
page_elements.sort(key=lambda a: a[0], reverse=True)
# 查找组成页面的元素
for i,component in enumerate(page_elements):
# 提取PDF中元素顶部的位置
pos= component[0]
# 提取页面布局的元素
element = component[1]
# 检查该元素是否为文本元素
if isinstance(element, LTTextContainer):
# 检查文本是否出现在表中
if table_extraction_flag == False:
# 使用该函数提取每个文本元素的文本和格式
(line_text, format_per_line) = text_extraction(element)
# 将每行的文本追加到页文本
page_text.append(line_text)
# 附加每一行包含文本的格式
line_format.append(format_per_line)
page_content.append(line_text)
else:
# 省略表中出现的文本
pass
# 检查元素中的图像
if isinstance(element, LTFigure):
# 从PDF中裁剪图像
crop_image(element, pageObj)
# 将裁剪后的pdf转换为图像
convert_to_images('cropped_image.pdf')
# 从图像中提取文本
image_text = image_to_text('PDF_image.png')
text_from_images.append(image_text)
page_content.append(image_text)
# 在文本和格式列表中添加占位符
page_text.append('image')
line_format.append('image')
# 检查表的元素
if isinstance(element, LTRect):
# 如果第一个矩形元素
if first_element == True and (table_num+1) <= len(tables):
# 找到表格的边界框
lower_side = page.bbox[3] - tables[table_num].bbox[3]
upper_side = element.y1
# 从表中提取信息
table = extract_table(pdf_path, pagenum, table_num)
# 将表信息转换为结构化字符串格式
table_string = table_converter(table)
# 将表字符串追加到列表中
text_from_tables.append(table_string)
page_content.append(table_string)
# 将标志设置为True以再次避免该内容
table_extraction_flag = True
# 让它成为另一个元素
first_element = False
# 在文本和格式列表中添加占位符
page_text.append('table')
line_format.append('table')
# 检查我们是否已经从页面中提取了表
if element.y0 >= lower_side and element.y1 <= upper_side:
pass
elif not isinstance(page_elements[i+1][1], LTRect):
table_extraction_flag = False
first_element = True
table_num+=1
# 创建字典的键
dctkey = 'Page_'+str(pagenum)
# 将list的列表添加为页键的值
text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]
# 关闭pdf文件对象
pdfFileObj.close()
# 删除已创建的过程文件
os.remove('cropped_image.pdf')
os.remove('PDF_image.png')
# 显示页面内容
result = ''.join(text_per_page['Page_0'][4])
print(result)
上面的脚本将运行:
导入必要的库;
使用pyPDF2库打开PDF文件;
提取PDF的每个页面并重复以下步骤;
检查页面上是否有任何表,并使用pdfplumner创建它们的列表;
查找页面中嵌套的所有元素,并按照它们在页面布局中出现的顺序对它们进行排序。
然后对于每个元素:
检查它是否是一个文本容器,并且没有出现在表元素中。然后使用text_extraction()函数提取文本及其格式,否则传递该文本。
检查它是否为图像,并使用crop_image()函数从PDF中裁剪图像组件,使用convert_to_images()将其转换为图像文件,并使用image_to_text()函数使用OCR从中提取文本。
检查它是否是一个矩形元素。在这种情况下,我们检查第一个矩形是否是页表的一部分,如果是,我们移动到以下步骤:
1.
查找表的边界框,以便不再使用text_extraction()函数提取其文本。
2.
提取表的内容并将其转换为字符串。
3.
然后添加一个布尔参数来说明我们是从Table中提取文本的。
4.
此过程将在最后一个LTRect落在表的边界框中并且布局中的下一个元素不是矩形对象之后结束。(构成表的所有其他对象都将被传递)
每次迭代的输出将存储在5个列表中,命名为:
1.
page_text:包含来自PDF中文本容器的文本(当文本从另一个元素中提取时,将放置占位符)
2.
Line_format:包含上面提取的文本的格式(当文本从另一个元素提取时,将放置占位符)
3.
Text_from_images:包含从页面上的图像中提取的文本
4.
Text_from_tables:包含带有表内容的类表字符串
5.
Page_content:以元素列表的形式包含页面上呈现的所有文本
所有的列表将被存储在字典的关键,将代表每次检查页面的数量。
之后,我们将关闭PDF文件。
然后,我们将删除在此过程中创建的所有附加文件。
最后,我们可以通过连接page_content列表的元素来显示页面的内容。
最后
我认为这是一种利用了各种库的最佳特性的方法,使过程能够适应我们可能遇到的各种类型的pdf和元素,但PDFMiner完成了大部分繁重的工作。同时,信息的格式文本可以帮助我们识别潜在的标题文本分离成不同的逻辑部分而不是每个页面内容并可以帮助我们识别文本更重要的。
然而,总是会有更有效的方法来做这个任务,尽管我认为这种方法是更具包容性。
引用
1.
https://www.techopedia.com/12-practical-large-language-model-llm-applications
2.
https://www.pdfa.org/wp-content/uploads/2018/06/1330_Johnson.pdf
3.
https://pdfpro.com/blog/guides/pdf-ocr-guide/#:~:text=OCR technology
reads text from, a searchable and editable PDF.
4.
https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#id1
5.
https://github.com/pdfminer/pdfminer.six
6.
Google Tesseract OCR:https://github.com/tesseract-ocr/tesseract
出自:https://mp.weixin.qq.com/s/4mg59Sb7TzaoXVctEMJVWw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip